能否使用PIPE与运行中的进程通信
PIPE通信是否仅限于有亲缘关系的进程
答案是对的
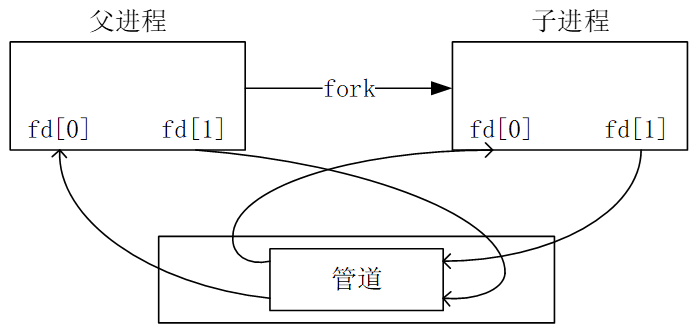
PIPE的官方定义是这样的:在Linux中,管道是一种特殊的文件,它是一种半双工的通信方式,只能用于具有亲缘关系的进程间通信。管道的创建需要使用pipe()函数,该函数会创建一个管道,返回两个文件描述符,分别指向管道的两端。管道的一端用于读,另一端用于写。管道的读端和写端是互斥的,即一个进程只能读,另一个进程只能写。管道的读端和写端都是阻塞的,即读端没有数据时,读进程会被阻塞,写端没有空间时,写进程会被阻塞。
PIPE只能用于父子进程间的通信,而且是半双工的,也就是说,只能单向通信。如果你想要双向通信,那么你需要两个PIPE,一个用于父进程向子进程通信,另一个用于子进程向父进程通信。
在下面代码中,实现了父进程和子进程通过PIPE的通信
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main() {
int _pipe[2];
int ret = pipe(_pipe);
if(ret < 0) {
perror("pipe\n");
}
pid_t id = fork();
if(id < 0) {
perror("fork\n");
}
else if(id == 0) { // child
close(_pipe[1]);
int j = 0;
char _mesg[100];
while(j < 100)
{
memset(_mesg,'\0',sizeof(_mesg ));
read(_pipe[0],_mesg,sizeof(_mesg));
printf("%s\n",_mesg);
j++;
sleep(1);
}
}
else //father
{
close(_pipe[0]);
int i = 0;
char *mesg = NULL;
while(i < 100)
{
mesg = "I am father";
write(_pipe[1], mesg, strlen(mesg)+1);
sleep(1);
++i;
}
}
return 0;
}但是,如果我们创建一个进程后,试图将PIPE的文件描述符从一个进程传递给另一个进程,是无法建立通信的。比如下面的代码,我们在pipe-test1.cpp中初始化的pipe,然后将pipe的文件描述符打印到终端。然后在另一个终端,运行pipe-test2.cpp,并以参数的形式将文件描述符传入。但是,pipe-test2.cpp中的代码并不能读取到pipe-test1.cpp中写入的数据。
// pipe-test1.cpp
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<iostream>
using namespace std;
int main(){
int _pipe[2];
int ret = pipe(_pipe);
if (ret < 0) {
perror("pipe\n");
}
cout<<_pipe[0]<<'\n';
cout<<_pipe[1]<<'\n';
// 关闭读端
close(_pipe[0]);
int i = 0;
char *mesg = NULL;
while(i < 100){
mesg = "hello world";
write(_pipe[1], mesg, strlen(mesg)+1);
sleep(1);
i++;
}
return 0;
}//pip-test2.cpp
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<iostream>
using namespace std;
int main(int argc, char *argv[]){
// 关闭写端
close(stoi(argv[2]));
int j=0;
char _mesg[100];
while(j<100){
memset(_mesg, '\0', sizeof(_mesg));
read(stoi(argv[1]), _mesg, sizeof(_mesg));
printf("%s\n", _mesg);
j++;
sleep(1);
}
return 0;
}能否通过PIPE与一个已经在运行的进程建立通信
答案是不能
原因其实在上面已经解释清楚了,因为新建立的进程和已经在运行的进程之间没有亲缘关系,所以无法通过PIPE建立通信。
其他通信方式
这其实也是我实际中遇到的一个问题:在B进程启动之前,A进程已经启动,并在stdout中持续输出消息,要求B与A建立通信,能够实时获取stdout中输出的信息。
这个问题的难点在于A进程在启动时,其stdout进行了重定向。一般我们通过shell启动一个进程时,如果没有显式重定向stdout,那么会默认为重定向到shell中即/dev/pty,如果要想B和A建立通信,需要A获取到B进程的PID,并使用dup2()和fcntl()方法,主动修改stdout的重定向。但是A进程在B进程之前启动,A进程很难获取到B进程的PID。
首先,我想到了使用tail -f去查看/proc/{A's PID}/fd/1的内容,该缓存文件实际上存储的是A进程stdout的内容(虽然是文件,但是其实际的位置其实是在内存或缓存中,只是有一个文件标志inode)。但是我发现这样行不通,原因在于stdout重定向是唯一的,当stdout进行重定向的时候,该缓存文件是无法被cat和tail的。
其次,可以用socket或者named pipe将A进程作为一个服务,只需要监听B进程的到来即可,但是这有点违背了设计的初衷,起初设计的是将A进程作为一个工具而不是一个服务。
最后,我采用了用文件或数据库作为中间存储,A进程将stdout重定向到文件或数据库中,B进程通过tail该文件和数据库进行实时获取最新内容。以下是项目中python的实现代码。
# 执行cmd的子进程为A进程,该cmd会不断输出stdout。
# 将该文件的唯一标识unique_id和A进程的PID返回给B进程
# 使用hashlib计算unique_id
hash_object = hashlib.md5(cmd.encode())
hash_value = int.from_bytes(hash_object.digest(), byteorder='big')
modulus = 10**9 + 7;
unique_id = hash_value % modulus
popen = Popen(cmd, shell=True, stdout=open(f'{unique_id}.out', 'w'))
pid = popen.pid
return unique_id, pid# B进程启动了一个子进程用于tail
if os.path.exists(filename):
cmd = ["tail", "-f", filename]
popen = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout = popen.stdout
if stdout:
# stdout的读取改为非阻塞模式,这样不会死锁,可以根据A进程的运行状态来判断是否继续读取
stdout_fd = stdout.fileno()
flags = fcntl.fcntl(stdout_fd, fcntl.F_GETFL)
fcntl.fcntl(stdout_fd, fcntl.F_SETFL, flags | os.O_NONBLOCK)
while popen.poll() is None and process.is_running():
ready, _, _ = select.select([stdout], [], [], 0)
if ready:
output = stdout.readline()总之可以看到,PIPE的使用还是有很多限制的,特别是与正在运行中的非亲缘关系的进程建立通信,这种情况下最好还是使用socket或named pipe,做成类似于C/S架构。否则只能通过文件或数据库作为中间存储,这样会经过硬盘或者云,显然性能上会下降很多。
